|
I am a fourth year Ph.D. candidate in Computer Science in Multimodal Vision Research Laboratory (MVRL) at Washington University in St. Louis, advised by Prof. Nathan Jacobs. Before that, I received my bachelor's degree in Electrical and Information Engineering from Tianjin University. I spent a wonderful year at Institute of Automation, Chinese Academy of Sciences(CASIA), working with Prof. Jinqiao Wang and Dr. Xu Zhao. I was a research intern at Bosch Research(Sunnyvale), OPPO US Research Center(Palo Alto) and OPPO Research(Beijing). Email / CV / Google Scholar / Linkedin / Github |

|
|
[01/2026] Start research internship at ByteDance, Intelligent Creation Lab (San Jose) in Spring 2026. |
|
My research lies broadly in computer vision and multi-modal learning, especially generative models and AIGC-related topics, In particular: (1) Unifying vision understanding and generation, world models; (2) Controllable \& personalized image/video generation and editing; (3) Integration of vision-language models (VLMs) with generative modeling; (4) Generative AI for 3D vision, including neural rendering, cross-view synthesis, and novel view synthesis. I am also interested in geometric computer vision and its combination with generative models. I am actively looking for 2026 summer/fall research internship. Feel free to chat or shoot me email for discussing any potential opportunities. |
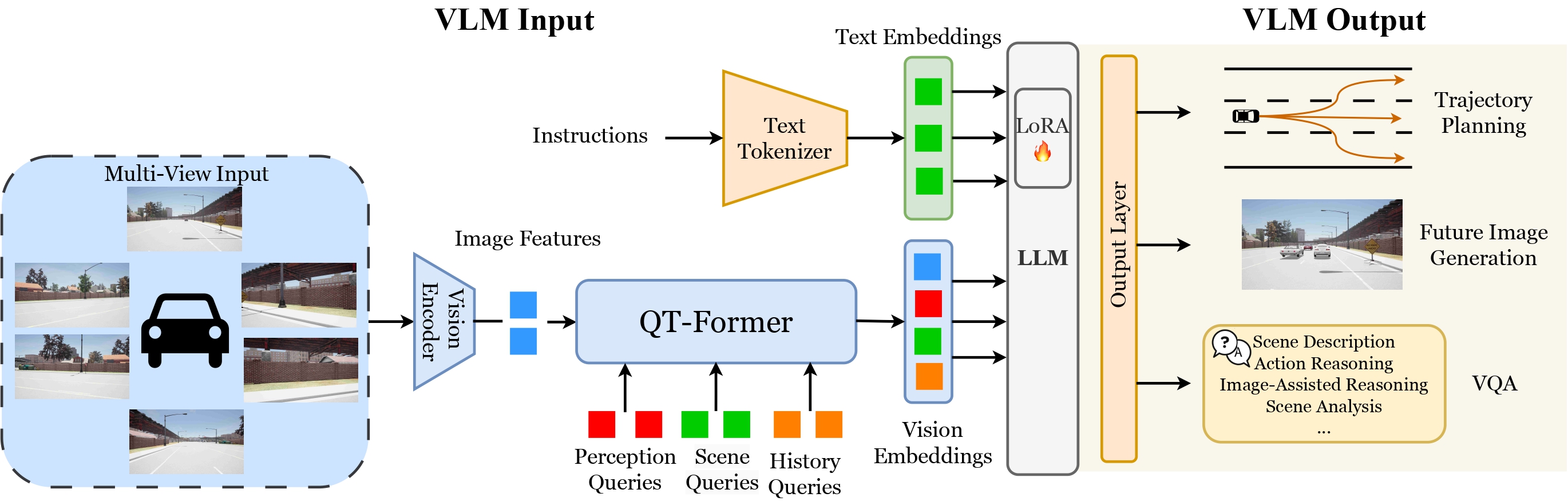
|
Zhexiao Xiong, Xin Ye, Burhan Yaman, Sheng Cheng, Yiren Lu, Jingru Luo, Nathan Jacobs, Liu Ren (In Submission) arXiv Developed a world-model-based framework that unifies trajectory planning and autoregressive future image generation, enhanced with Chain-of-Thought reasoning within a single vision-language model (VLM). Enabled visual thinking, leading to more accurate and robust decision-making, and demonstrated significant gains on vision-language planning(VLP) benchmarks. |
|
Zhexiao Xiong, Yizhi Song, Liu He, Wei Xiong, Yu Yuan, Feng Qiao, Nathan Jacobs (In Submission) project page / arXiv Proposed a framework that leverages vision-language model(VLM)'s physics understanding to enable video generation with physically consistent motion and accurate 3D dynamics. Achieved physically plausible video generation by combining relational alignment with foundation video understanding models, physics-aware feature encoding, and 3D geometry alignment. |

|
Zhexiao Xiong, Wei Xiong, Jing Shi, He Zhang, Yizhi Song, Nathan Jacobs Transactions on Machine Learning Research (TMLR), 2025 Recent studies in text-to-image customization show great success in generating personalized object variants given several images of a subject. While existing methods focus more on preserving the identity of the subject, they often fall short of controlling the spatial relationship between objects. In this work, we introduce GroundingBooth, a framework that achieves zero-shot instance-level spatial grounding on both foreground subjects and background objects in the text-to-image customization task. Our proposed text-image grounding module and masked cross-attention layer allow us to generate personalized images with both accurate layout alignment and identity preservation while maintaining text-image coherence. With such layout control, our model inherently enables the customization of multiple subjects at once. Our model is evaluated on both layout-guided image synthesis and reference-based customization tasks, showing strong results compared to existing methods. Our work is the first work to achieve a joint grounding of both subject-driven foreground generation and text-driven background generation. The project page is available at https://groundingbooth.github.io. |
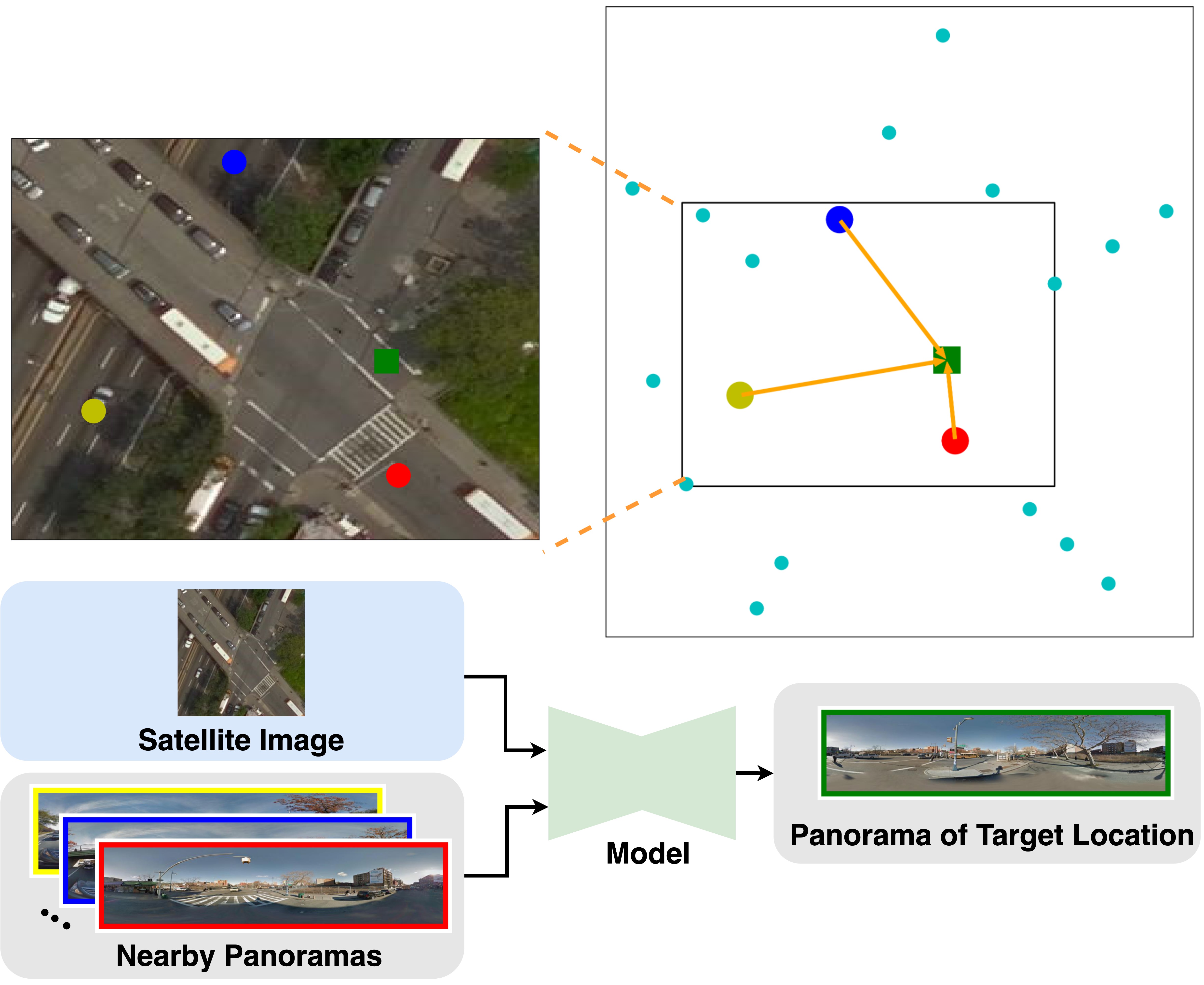
|
Zhexiao Xiong, Xin Xing, Scott Workman, Subash Khanal, Nathan Jacobs Transactions on Machine Learning Research (TMLR), 2025 project page / arXiv We introduce the task of mixed-view panorama synthesis, where the goal is to synthesize a novel panorama given a small set of input panoramas and a satellite image of the area. This contrasts with previous work which only uses input panoramas (same-view synthesis), or an input satellite image (cross-view synthesis). We argue that the mixed-view setting is the most natural to support panorama synthesis for arbitrary locations worldwide. A critical challenge is that the spatial coverage of panoramas is uneven, with few panoramas available in many regions of the world. We introduce an approach that utilizes diffusion-based modeling and an attention-based architecture for extracting information from all available input imagery. Experimental results demonstrate the effectiveness of our proposed method. In particular, our model can handle scenarios when the available panoramas are sparse or far from the location of the panorama we are attempting to synthesize. The project page is available at https://mixed-view.github.io. |

|
Feng Qiao, Zhexiao Xiong, Eric Xing, Nathan Jacobs International Conference on Computer Vision(ICCV), 2025 project page / arXiv Existing stereo image generation methods typically focus on either visual quality for viewing or geometric accuracy for matching, but not both. We introduce GenStereo, a diffusion-based approach, to bridge this gap. The method includes two primary innovations (1) conditioning the diffusion process on a disparity-aware coordinate embedding and a warped input image, allowing for more precise stereo alignment than previous methods, and (2) an adaptive fusion mechanism that intelligently combines the diffusion-generated image with a warped image, improving both realism and disparity consistency. Through extensive training on 11 diverse stereo datasets, GenStereo demonstrates strong generalization ability. GenStereo achieves state-of-the-art performance in both stereo image generation and unsupervised stereo matching tasks. |
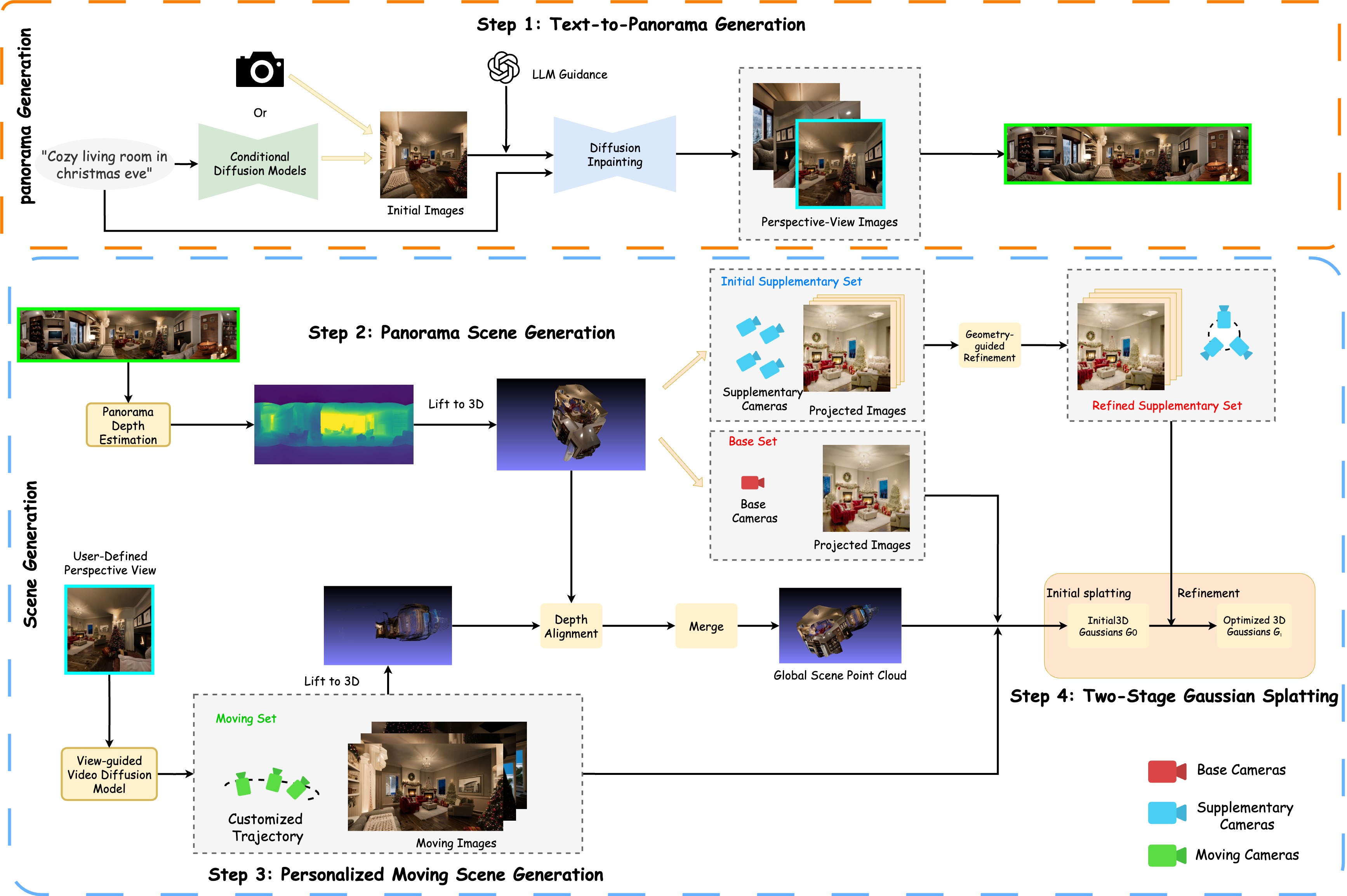
|
Zhexiao Xiong, Zhang Chen, Zhong Li, Yi Xu, Nathan Jacobs IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops(CV4Metaverse), 2025 We propose PanoDreamer, a holistic text to 360-degree scene generation pipeline, which achieves consistent text-to-360-degree scene generation with customized trajectory-guided scene extension. We introduce semantically guided novel view synthesis into the refinement of 3D-GS optimization, reducing artifacts and improving geometric consistency. Experiments show the effectiveness of our model in generating geometrically consistent and high-quality 360-degree scenes. |
|
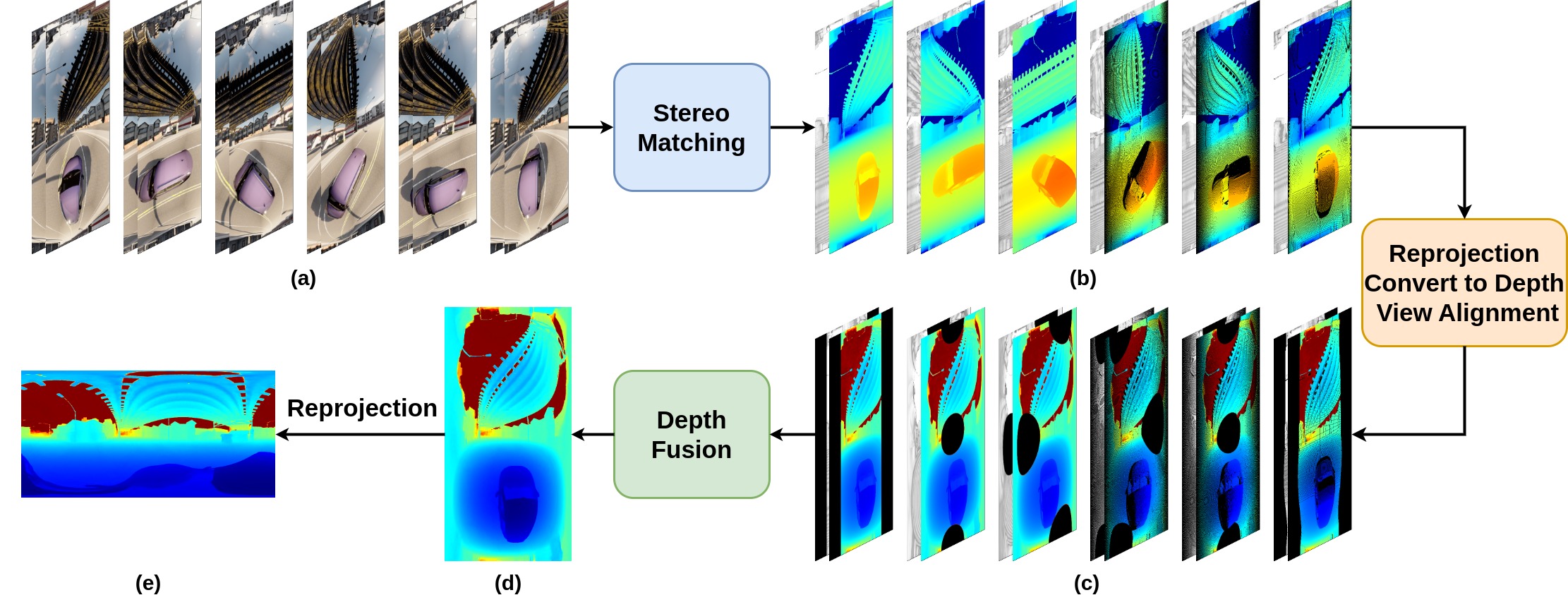
Feng Qiao, Zhexiao Xiong, Xinge Zhu, Yuexin Ma, Qiumeng He, Nathan Jacobs IEEE/CVF Winter Conference on Applications of Computer Vision(WACV), 2026 We introduce Multi-Cylindrical Panoramic Depth Estimation (MCPDepth), a two-stage framework for omnidirectional depth estimation via stereo matching between multiple cylindrical panoramas. MCPDepth uses cylindrical panoramas for initial stereo matching and then fuses the resulting depth maps across views. A circular attention module is employed to overcome the distortion along the vertical axis. MCPDepth exclusively utilizes standard network components, simplifying deployment to embedded devices and outperforming previous methods that require custom kernels. We theoretically and experimentally compare spherical and cylindrical projections for stereo matching, highlighting the advantages of the cylindrical projection. MCPDepth achieves state-of-the-art performance with an 18.8% reduction in mean absolute error (MAE) for depth on the outdoor synthetic dataset Deep360 and a 19.9% reduction on the indoor real-scene dataset 3D60. |
|
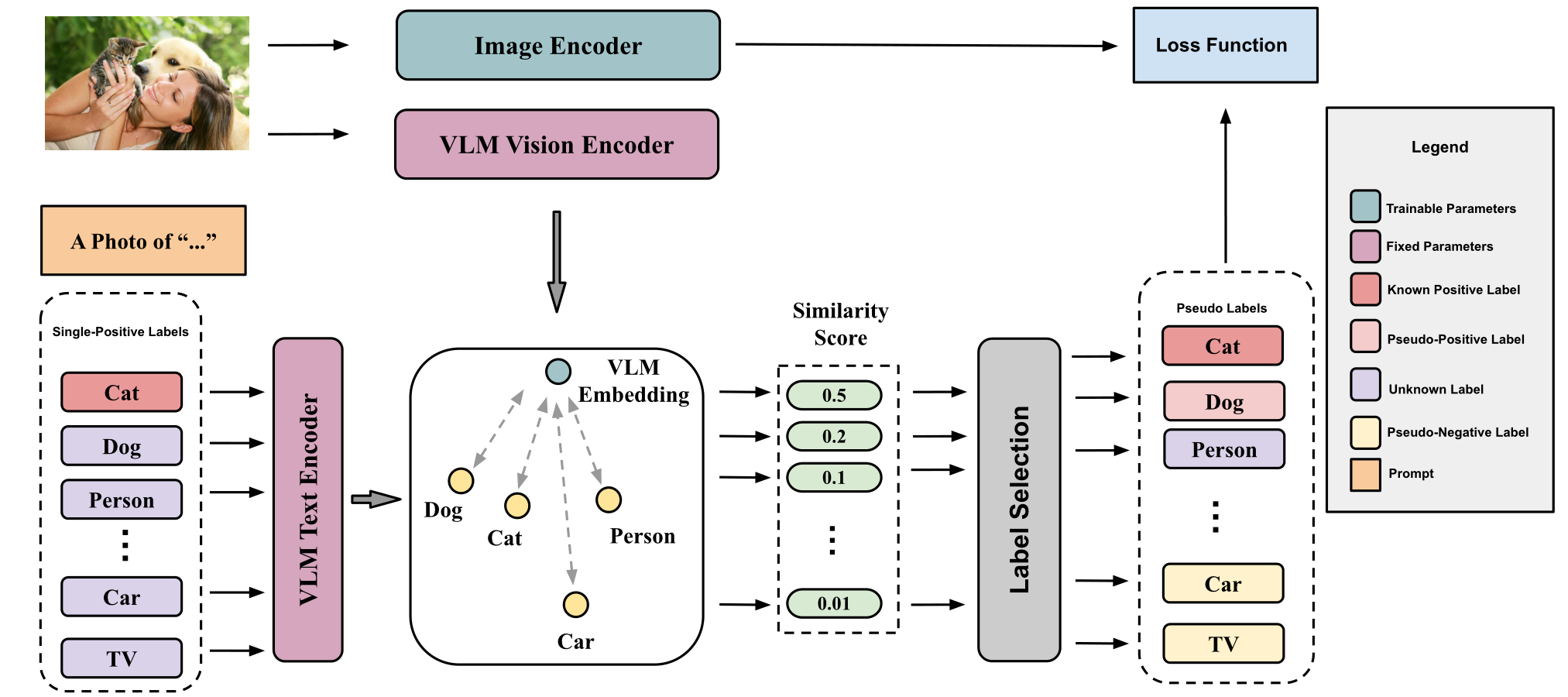
Xin Xing, Zhexiao Xiong, Abby Stylianou, Srikumar Sastry, Liyu Gong , Nathan Jacobs IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops(CVPRW), 2024 arXiv We propose a novel approach called Vision-Language Pseudo-Labeling (VLPL), which uses a visionlanguage model to suggest strong positive and negative pseudo-labels, and outperform the current SOTA methods by 5.5% on Pascal VOC, 18.4% on MS-COCO, 15.2% on NUS-WIDE, and 8.4% on CUB-Birds. |
|
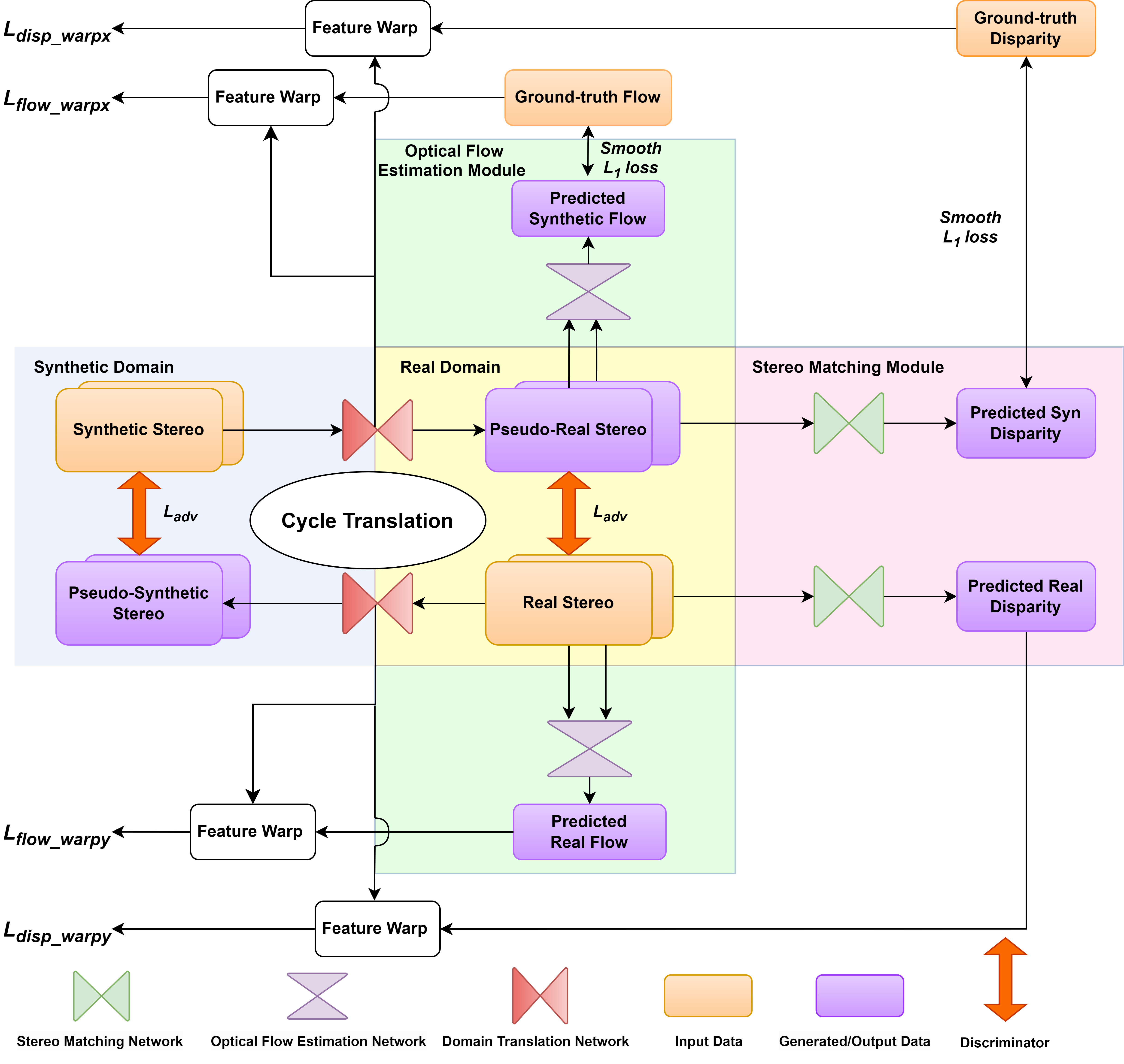
Zhexiao Xiong, Feng Qiao, Yu Zhang, Nathan Jacobs, British Machine Vision Conference (BMVC), 2023 arXiv We introduce a novel training strategy for stereo matching and optical flow estimation that utilizes image-to-image translation between synthetic and real image domains. Our approach enables the training of models that excel in real image scenarios while relying solely on ground-truth information from synthetic images. To facilitate task- agnostic domain adaptation and the training of task-specific components, we introduce a bidirectional feature warping module that handles both left-right and forward-backward directions. Experimental results show competitive performance over previous domain translation-based methods, which substantiate the efficacy of our proposed framework, effectively leveraging the benefits of unsupervised domain adaptation, stereo matching, and optical flow estimation. |

|
Nanfei Jiang , Zhexiao Xiong, Hui Tian , Xu Zhao, Xiaojie Du , Chaoyang Zhao , Jinqiao Wang, Cognitive Computation and Systems We propose a network pruning pipeline,PruneFaceDet, to prune the lightweight face detection network, which performs training with L1 regularisation before CP. We compare two thresholding methods to get proper pruning thresholds in the CP stage. We apply the proposed pruning pipeline on the lightweight face detector and evaluate the performance on the WiderFace dataset, and get the result of a 56.3% decline of parameter size with almost no accuracy drop. |
|
Conference Reviewer: CVPR 2025/2026, ECCV 2024/2026, ICCV 2025, NeurIPS 2024/2025, ICLR 2025, ICML 2025 |
|
|
|
|
ByteDance |
|
|
Bosch Research |
|
|
OPPO US Research Center |
|
|
OPPO Research Institute |
|
|
Institute of Automation, Chinese Academy of Sciences (CASIA) |
|
Thank Jon Barron for sharing his website's source code. |